摘要:记录对 hadoop 工作原理的研究感悟,以及一些常用的使用方法。
hadoop 集群
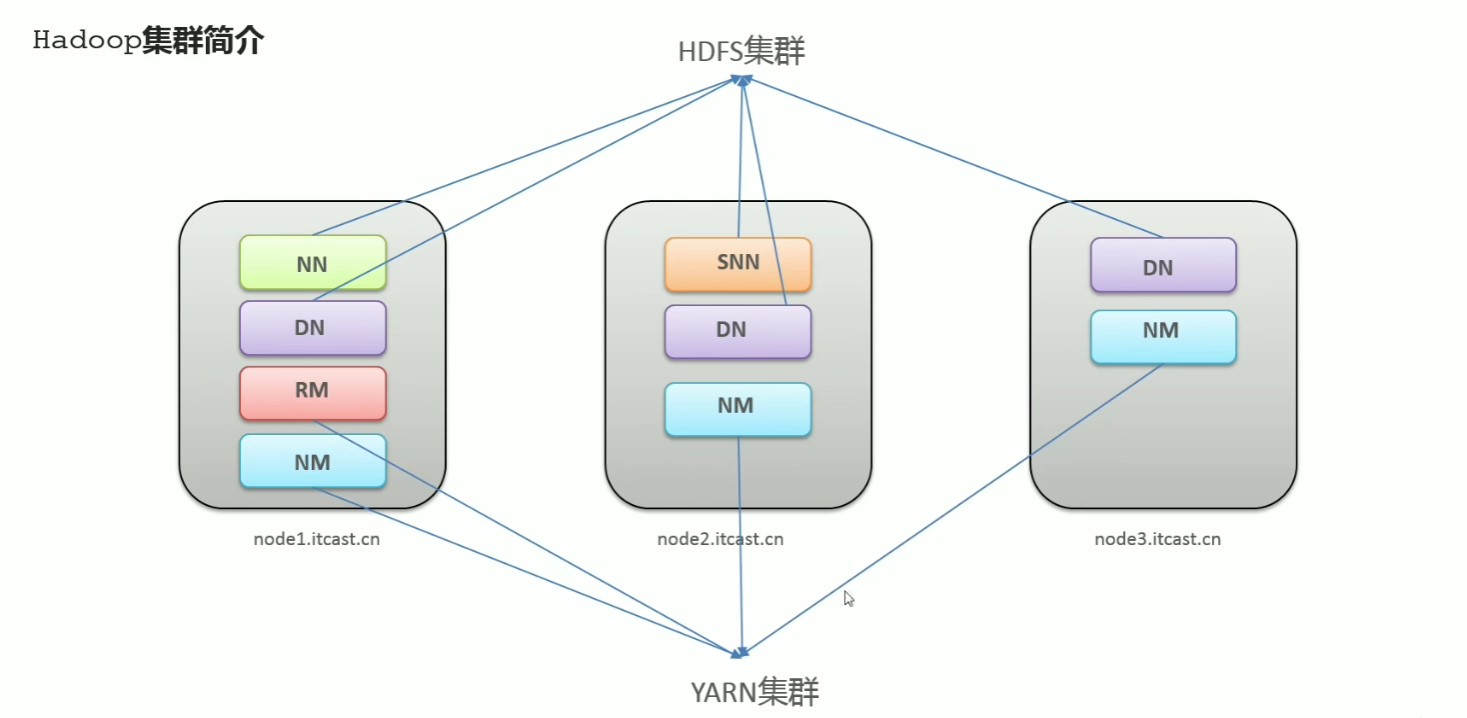
HDFS(文件存储系统):
其中 node1 为命名节点(namennode)存放主机,用于指挥其他两台存放数据节点(DataNode)的主机
YARN:
node1 为资源管理(resourcemanager)存放主机负责整合资源,其他两台主机存放节点管理(nodemanager)负责存储元数据信息
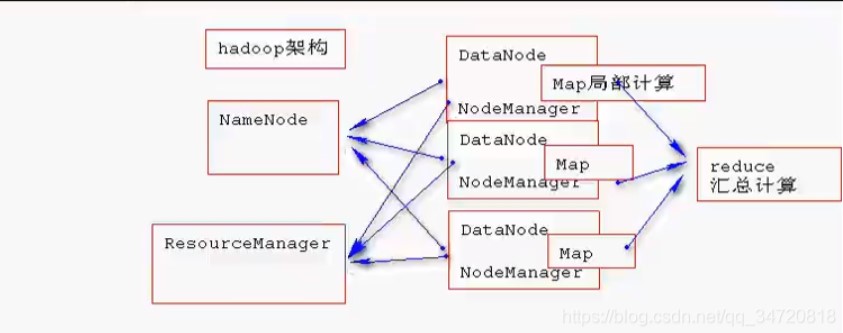
yarn 集群和 hdfs 集群进行共同工作,hdfs 集群存储数据,yarn 集群调度资源进行计算。
常用命令
hadoop fs -put -文件上传
hadoop fs -get -文件下载
hadoop fs -appendToFile -文件追加(合并)
核心配置文件
hadoop-env.sh
export JAVA_HOME -指定jdk环境
# 授予root用户使用权限
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
yarn-env.sh 同上
core-site.xml
<!-- 指定hdfs分布式文件存储系统的路径 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nn:9000</value>
</property>
<!-- 临时数据存放的位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///home/hadoop/tmp</value>
</property>
<!-- 设置HDFSWEB UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
hdfs-site.xml
<!-- NameNode 数据的存放地点。也就是namenode元数据存放的地方,记录了hdfs系统中文件的元数据-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/name</value>
</property>
<!-- HDFS 的副本数设置。也就是上传一个文件,其分割为block块后,每个block的冗余副本个数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondary NameNode 的访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>dn1:9868</value>
</property>
mapred-site.xml
<!-- 指定mr框架为yarn方式,Hadoop二代MP也基于资源管理系统Yarn来运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 开启mapreduce的小任务模式,用于调优 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 配置mapreduce的jobhistory内部通讯地址。可以查看我们所有运行完成的任务的一些情况 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>nn:10020</value>
</property>
<!-- 配置mapreduce 的jobhistory的访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nn:19888</value>
</property>
yarn-site.xml
<!-- 指定我们的resourceManager运行在哪台机器上面 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nn</value>
</property>
<!-- NodeManager的通信方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 日志的聚合功能,方便我们查看任务执行完成之后的日志记录 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 聚合日志的保存时长 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--yarn总管理器的IPC通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>nn:8032</value>
</property>
<!--yarn总管理器调度程序的IPC通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>nn:8030</value>
</property>
<!--yarn总管理器的IPC通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>nn:8031</value>
</property>
<!--yarn总管理器的IPC管理地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>nn:8033</value>
</property>
<!--yarn总管理器的web http通讯地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>nn:8088</value>
</property>
workers -记录存放从机工作的主机名
dn1
dn2